Entries from August 2012 ↓
August 15th, 2012 — Data management
Jaspersoft has released the results of its latest Big Data Survey and was good enough to share with us a few additional details. It makes for interesting reading.
The first thing to take into account is the sample bias. The survey was conducted with over 600 Jaspersoft community members. 63% of respondents are application developers, and 37% are in the software and Internet industry.
This already speaks volumes about the sectors with interest in big data, and it is interesting to compare the state of big data adoption with the recent results of 451 Research’s TheInfoPro storage study, which is conducted with storage professionals.
According to that study, 24% of storage respondents had already implemented solutions for big data, while 56% had no plans. As you might expect, Jaspersoft’s sample was more keen, with 36% having already deployed or in development, and 38% with no plans.
That’s still a good proportion of respondents with no plans to adopt a big data analytics project, however, with the biggest reasons not to adopt being a reliance on structured data (37%) and no clear understanding of what ‘big data’ is (35%).
Sceptics might suggest that the respondents to Jaspersoft’s survey that do have plans for big data are also somewhat confused about what constitutes a big data project.
Certainly they are using some fairly traditional technologies and approaches. Looking at the most popular answers to a range of questions we find that those with big data plans are:
- creating reports (76%)
- to analyze customer experience (48%)
- based on data from enterprise applications (79%)
- stored on relational databases (60%)
- processed using ETL (59%)
- running on-premises (60%)
So far, so what. The characteristics above could be used to describe many existing business intelligence projects.
It’s not even as if respondents are looking at huge volumes of data, with 38% expecting total data volume to be in the gigabytes, 40% expecting terabytes, and just 10% expecting petabytes and above.
So what makes these big data projects? It’s not until you look at the source of the data that you get any sense that the respondents with ongoing big data projects are doing anything different from those without: 68% are using machine-generated content (web logs, sensor data) as the a source for their big data projects, and 46% are using human-generated text (social media, blogs).
The results do suggest that some non-traditional analytics and data processing approaches are gaining ground, with 64% citing the importance of data visualization, 54% statistical/predictive analytics, 50% search, and 45% text analytics. However, just 18% are using Hadoop HDFS at this point (behind MongoDB with 19%).
August 14th, 2012 — Data management
Datomic calls time on RDBMS. Actian offers $154m for Pervasive. And more
And that’s the Data Day, today.
August 10th, 2012 — Data management
HP’s Autonomy problem. Excel 2013. And more.
And that’s the Data Day, today.
August 10th, 2012 — Data management
Back in December we published an assessment on the distribution of Hadoop skills, based on LinkedIn search results.
Thanks to a temporary lull in GB’s Olympic medal-winning exploits I ran the search again the other day. The results are pretty interesting for a number of reasons.
First the headline stats:
- There are over 22,000 people with Hadoop in their LinkedIn profiles, up from just over 9,000 in December 2011, an increase of over 144% in eight months.
- Hadoop skills are becoming more evenly distributed: 60.4% of LinkedIn members with Hadoop in the profiles are based in the US, compared to 64.5% in December 2011.
- Growth areas include India (11.9% from 9.7%), China (4.4% from 3.6%, and the UK (3.4% from 3.0%).
- However, the Bay Area remains the best place to find Hadoop enthusiasts, with 24.9% (albeit down from 28.2% eight months ago)

This time I also ran a similar search for MapReduce skills. The headline results:
- MapReduce is mentioned in 6,424 LinkedIn profiles.
- MapReduce skills are more evenly distributed: 61.9% of LinkedIn members with MapReduce in their profiles are based in the US, 38.1% in the rest of the world.
- That said, over a quarter (25.9%) of LinkedIn members with MapReduce in their profiles are based in the Bay area.
- Other geographic hotspots are India (8.7%), Seattle area (5.8%), and NYC area (4.8%).
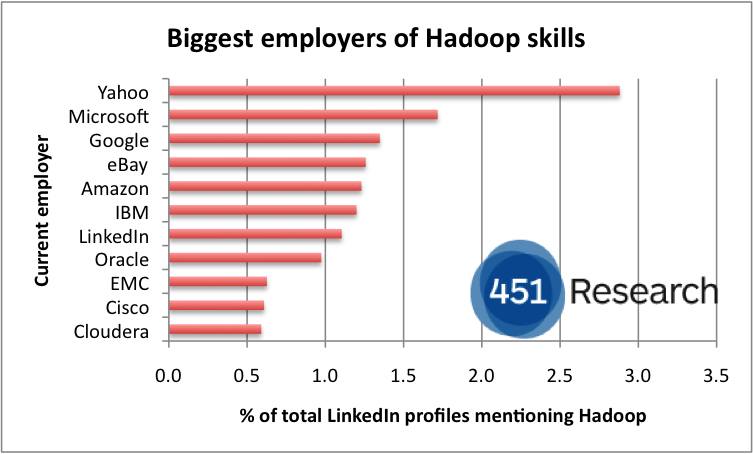
This time I also looked at which vendors are listed as the current employers of LinkedIn members citing Hadoop and MapReduce. One really surprising result stood out:
- Microsoft is the second largest employer of both Hadoop and MapReduce skills, according to LinkedIn member profiles
- Redmond employs 1.7% of all LinkedIn members with Hadoop in their profiles, and 3.0% of members with MapReduce in their profiles
- Yahoo is the largest employer of Hadoop skills (2.9%), with other ‘non-vendors’ also well represented: Google (1.3%), eBay (also 1.3%), Amazon (1.2%), LinkedIn (1.1%).
- Google is by far the largest employer of MapReduce skills, as you might expect, with 7.1%. Also well represented are Yahoo (2.7%), Amazon (1.8%) and LinkedIn (1.4%).

August 8th, 2012 — Data management
Who loves Hadoop? Who doesn’t?
And that’s the Data Day, today.
August 7th, 2012 — Data management
Hadapt goes GA (quietly). Birst delivers Distributed Business Analytics
And that’s the Data Day, today.
August 3rd, 2012 — Data management
StormDB looks to define database cloud. YARN becomes Hadoop sub-project. And more.
And that’s the Data Day, today.
August 1st, 2012 — Data management
Rapid-I integrates with Radoop. How ‘Big Data’ Is Different. And more.
And that’s the Data Day, today.

 Subscribe via RSS
Subscribe via RSS