September 30th, 2015 — Data management
What is Hadoop?
It should be fairly simple: in the beginning there was the Hadoop Distributed File System, Hadoop MapReduce, and the Hadoop Common set of utilities. Even with the addition of Apache YARN in 2013, just four projects officially form the core of Apache Hadoop.
However, this is not what most people refer to when they use the term ‘Hadoop’. Instead most people refer to the combination of Hadoop-related projects that are combined together with the Hadoop core to create Hadoop distributions.
As 451 Research’s Periodic Table of Hadoop illustrates, there are at least 40 projects that could be considered part of the Hadoop ecosystem (our table is comprised of Hadoop-related Apache Software Foundation projects, as well as other open source projects included in more than one Hadoop distribution). So ‘Hadoop’ represents pretty much any combination of more than 40 projects.

Hadoop’s creator Doug Cutting has asserted that Hadoop will evolve over time from a batch-processing engine to encompass a set of replaceable components in a wider distributed data-processing ecosystem. At the same time the word ‘Hadoop’ has evolved to become a catch-all brand for that wider distributed data-processing ecosystem.
That is potentially confusing, especially for for later mainstream adopters as they seek get their heads around what Hadoop is and what it is for. However, that’s not what this blog post is about. I’m less interested in defining what Hadoop is as I am interested in identifying what isn’t Hadoop.
When is Hadoop not Hadoop?
Recent announcements from the original Hadoop commercial supporter, Cloudera, have highlighted the significance of this question. First it anointed Spark as the successor to MapReduce, then it launched Kudu, a new storage engine and potential alternative to the Hadoop Distributed File System (HDFS).
If the company’s plans for Spark and Kudu play out, pretty soon we could see a whole lot of ‘Hadoop deployments’ that make use of neither MapReduce nor HDFS – the primary initial Hadoop core projects. This isn’t just a potential outcome. Already today it is perfectly plausible that a ‘Hadoop deployment’ might not involve MapReduce or HDFS – it could involve Spark accessing data in AWS S3 for example.
Both Spark and Kudu are open source and are clearly part of the wider Hadoop ecosystem, but where do you draw the line in terms of what is and isn’t ‘Hadoop’?
Vendors are increasingly layering additional proprietary components on top of this Hadoop ecosystem for differentiation. MapR has most obviously blurred the lines between Hadoop and not Hadoop, but Cloudera Enterprise could also arguably be put in a ‘Hadoop+’ category along with things like Pivotal Big Data Suite, and IBM BigInsights.
Then there are things that aren’t even claimed to be Hadoop but on closer inspection bear a close resemblance as ‘Hadoop’ evolves beyond its core. For example, the Stratio Platform is based on Apache Spark and other Apache projects including Flume and Kafka. It is isn’t claimed to be Hadoop but it enables data to be stored in the Hadoop Distributed File System (as well as AWS S3, Elasticsearch, MongoDB, Apache Cassandra, Redis, and relational databases) so it is surely part of the same wider family of data platforms.

If not Hadoop, then what?
So what should we call this wider family of data platforms – including Hadoop+ and ‘other’? Due to the pick-and-mix nature of the Hadoop ecosystem there is no easy way to answer that in terms of technology or use-cases. The products and services will be designed specifically to deliver a mix of data processing and storage capabilities, including MapReduce, SQL engines and stream processing, as well as HDFS, HBase, S3 and Kudu, and much more besides, both proprietary and open source.
Indeed it is probably easier to think about this not in terms of technologies but the symbols that represent them. If Hadoop was originally symbolised by an elephant then what symbol best conveys the category of data platforms based on the wider Hadoop ecosystem and beyond?
Given the veritable menagerie of animals (and inanimate objects) that represent the various Hadoop ecosystem projects – elephant, pig, bee, tortoise, falcon, giraffe, orca, squirrel, hippopotamus, antelope, phoenix, kylin, roadrunner, hummingbird – there is surely only one choice: the Chimera.

Source: Wikimedia
For those not acquainted with Greek mythology the Chimera was a fire-breathing, multi-headed hybrid creature composed of the parts of more than one animal. While Chimera was classically composed of the features of a lion, a snake and a goat, the term chimera can be used to describe any animal with parts taken from various animals.
As such it is perfect to symbolise the multi-headed hybrid Hadoop-based data platforms we see evolving. We are therefore tempted to use the term Chimeric Data Platform to describe this wider category of data platforms that are building on and expanding from Hadoop.
The fact that Merriam Webster further defines chimera as “something that exists only in the imagination and is not possible in reality” is an added bonus that appeals to our sense of humour.
March 28th, 2013 — Data management
Google pledges patent support for OSS. Basho open sources Riak CS. And more
And that’s the data day, today.
August 10th, 2012 — Data management
HP’s Autonomy problem. Excel 2013. And more.
And that’s the Data Day, today.
August 10th, 2012 — Data management
Back in December we published an assessment on the distribution of Hadoop skills, based on LinkedIn search results.
Thanks to a temporary lull in GB’s Olympic medal-winning exploits I ran the search again the other day. The results are pretty interesting for a number of reasons.
First the headline stats:
- There are over 22,000 people with Hadoop in their LinkedIn profiles, up from just over 9,000 in December 2011, an increase of over 144% in eight months.
- Hadoop skills are becoming more evenly distributed: 60.4% of LinkedIn members with Hadoop in the profiles are based in the US, compared to 64.5% in December 2011.
- Growth areas include India (11.9% from 9.7%), China (4.4% from 3.6%, and the UK (3.4% from 3.0%).
- However, the Bay Area remains the best place to find Hadoop enthusiasts, with 24.9% (albeit down from 28.2% eight months ago)

This time I also ran a similar search for MapReduce skills. The headline results:
- MapReduce is mentioned in 6,424 LinkedIn profiles.
- MapReduce skills are more evenly distributed: 61.9% of LinkedIn members with MapReduce in their profiles are based in the US, 38.1% in the rest of the world.
- That said, over a quarter (25.9%) of LinkedIn members with MapReduce in their profiles are based in the Bay area.
- Other geographic hotspots are India (8.7%), Seattle area (5.8%), and NYC area (4.8%).
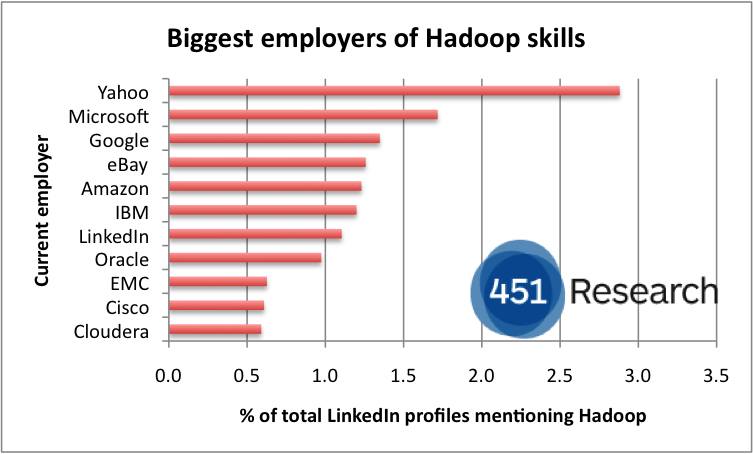
This time I also looked at which vendors are listed as the current employers of LinkedIn members citing Hadoop and MapReduce. One really surprising result stood out:
- Microsoft is the second largest employer of both Hadoop and MapReduce skills, according to LinkedIn member profiles
- Redmond employs 1.7% of all LinkedIn members with Hadoop in their profiles, and 3.0% of members with MapReduce in their profiles
- Yahoo is the largest employer of Hadoop skills (2.9%), with other ‘non-vendors’ also well represented: Google (1.3%), eBay (also 1.3%), Amazon (1.2%), LinkedIn (1.1%).
- Google is by far the largest employer of MapReduce skills, as you might expect, with 7.1%. Also well represented are Yahoo (2.7%), Amazon (1.8%) and LinkedIn (1.4%).

August 3rd, 2012 — Data management
StormDB looks to define database cloud. YARN becomes Hadoop sub-project. And more.
And that’s the Data Day, today.
July 20th, 2012 — Data management
StreamBase LiveView. ADVIZOR acquirers. The Accumulo Challenge. And more.
And that’s the Data Day, today.
August 5th, 2011 — Data management
Next Tuesday, August 3, at 8.30 AM PDT I’ll be taking part in a Webinar with Platform Computing to discuss the the benefits and challenges of Hadoop and MapReduce. Here’s the details:
With the explosion of data in the enterprise, especially unstructured data which constitutes about 80% of the total data in the enterprise, new tools and techniques are needed for business intelligence and big data processing. Apache Hadoop MapReduce is fast becoming the preferred solution for the analysis and processing of this data.
The speakers will address the issues facing enterprises deploying open source solutions. They will provide an overview of the solutions available for Big Data, discuss best practices, lessons learned, case studies and actionable plans to move your project forward.
To register for the event please visit the registration page.
August 3rd, 2011 — Data management
Continuing my recent exploration of Indeed.com’s job posting trends and data I have recently been taking a look at which organizations (excluding recruitment firms) are hiring Hadoop and MapReduce skills. The results are pretty interesting.
When it comes to who is hiring Hadoop skills, the answer, put simply, is Amazon, or more generally new media:

Source: Indeed.com Correct as of August 2, 2011
This is indicative of the early stage of adoption, and perhaps reflects the fact that many new media Hadoop adopters have chosen to self-support rather than turn to the Hadoop support providers/distributors.
It is no surprise to see those vendors also listed as they look to staff up to meet the expected levels of enterprise adoption (and it is worth noting that Amazon could also be included in the vendors category, given its Elastic MapReduce service).
Fascinating to see that of the vendors, VMware currently has the most job postings on Indeed.com referencing Hadoop, while Microsoft also makes an appearance.
Meanwhile the appearance of Northrop Grumman and Sears Holdings on this list indicates the potential for adoption in more traditional data management adopters, such as government and retail.
It is interesting to compare the results for Hadoop job postings with those mentioning Teradata, which shows a much more varied selection of retail, health, telecoms, and financial services providers, as well as systems integrators, government contractors, new media and vendors.
It is also interesting to compare Hadoop-related bog postings with those specifying MapReduce skills. There are a lot less of them, for a start, and while new media companies are well-represented, there is much greater interest from government contractors.

Source: Indeed.com Correct as of August 2, 2011
November 24th, 2010 — Data management
I was just looking through some slides handed to me by Cloudera’s John Kreisa and Mike Olson during our meeting last week and one of them jumped out at me.
It contains a graphic showing a Google Trends result for searches for Hadoop and “Big Data”. See for yourself why the graphic stood out:

In case you hadn’t guessed, Hadoop is in blue and “Big Data” is in red.
Even taken with a pinch of salt it’s a huge validation of the level of interest in Hadoop. Removing the quotes to search for Big Data (red) doesn’t change the overall picture.

See also Hadoop (blue) versus MapReduce (red).

UPDATE: eBay’s Oliver Ratzesberger puts the comparisons above in perspective somewhat by comparing Joomla vx Hadoop.

 Subscribe via RSS
Subscribe via RSS
{kind=link}