August 10th, 2012 — Data management
Back in December we published an assessment on the distribution of Hadoop skills, based on LinkedIn search results.
Thanks to a temporary lull in GB’s Olympic medal-winning exploits I ran the search again the other day. The results are pretty interesting for a number of reasons.
First the headline stats:
- There are over 22,000 people with Hadoop in their LinkedIn profiles, up from just over 9,000 in December 2011, an increase of over 144% in eight months.
- Hadoop skills are becoming more evenly distributed: 60.4% of LinkedIn members with Hadoop in the profiles are based in the US, compared to 64.5% in December 2011.
- Growth areas include India (11.9% from 9.7%), China (4.4% from 3.6%, and the UK (3.4% from 3.0%).
- However, the Bay Area remains the best place to find Hadoop enthusiasts, with 24.9% (albeit down from 28.2% eight months ago)

This time I also ran a similar search for MapReduce skills. The headline results:
- MapReduce is mentioned in 6,424 LinkedIn profiles.
- MapReduce skills are more evenly distributed: 61.9% of LinkedIn members with MapReduce in their profiles are based in the US, 38.1% in the rest of the world.
- That said, over a quarter (25.9%) of LinkedIn members with MapReduce in their profiles are based in the Bay area.
- Other geographic hotspots are India (8.7%), Seattle area (5.8%), and NYC area (4.8%).
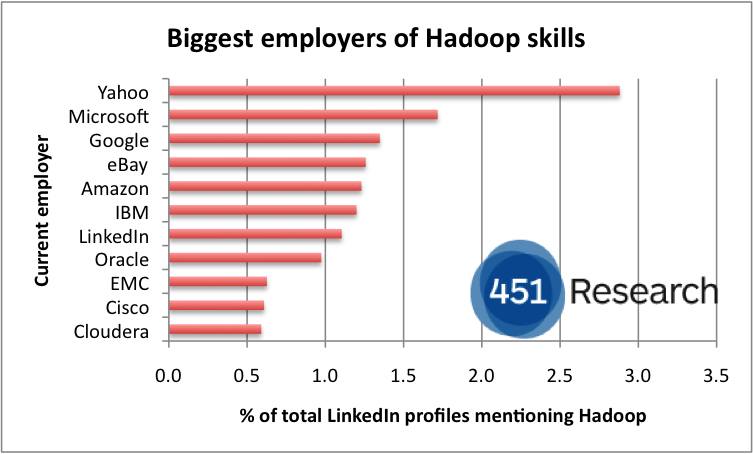
This time I also looked at which vendors are listed as the current employers of LinkedIn members citing Hadoop and MapReduce. One really surprising result stood out:
- Microsoft is the second largest employer of both Hadoop and MapReduce skills, according to LinkedIn member profiles
- Redmond employs 1.7% of all LinkedIn members with Hadoop in their profiles, and 3.0% of members with MapReduce in their profiles
- Yahoo is the largest employer of Hadoop skills (2.9%), with other ‘non-vendors’ also well represented: Google (1.3%), eBay (also 1.3%), Amazon (1.2%), LinkedIn (1.1%).
- Google is by far the largest employer of MapReduce skills, as you might expect, with 7.1%. Also well represented are Yahoo (2.7%), Amazon (1.8%) and LinkedIn (1.4%).

August 8th, 2012 — Data management
Who loves Hadoop? Who doesn’t?
And that’s the Data Day, today.
July 27th, 2012 — Data management
Special Twitter crash double edition. TransLattice, SAP, Lavastorm, QlikTech. And more.
And that’s the Data Day, today.
July 18th, 2012 — Data management
Basho enters Japan. US Senate/NSA open source policy and NoSQL design brouhaha.
And that’s the Data Day, today.
July 9th, 2012 — Data management
GigaOM published an interesting article over the weekend written by Cloudant’s Mike Miller about why the days are numbered for Hadoop as we know it.
Miller argues that while Google’s MapReduce and file system research inspired the rise of the Apache Hadoop project, Google’s subsequent research into areas such as incremental indexing, ad hoc analytics and graph analysis is likely to inspire the next-generation of data management technologies.
We’ve made similar observations ourselves but would caution against assuming, as some people appear to have done, that implementations of Google’s Percolator, Dremel and Pregel projects are likely to lead to Hadoop’s demise. Hadoop’s days are not numbered. Just Hadoop as we know it.
Miller makes this point himself when he writes “it is my opinion that it will require new, non-MapReduce-based architectures that leverage the Hadoop core (HDFS and Zookeeper) to truly compete with Google’s technology.”
As we noted in our 2011 Total Data report:
“it may be that we see more success for distributed data processing technologies that extend beyond Hadoop’s batch processing focus… Advances in the next generation of Hadoop delivered in the 0.23 release will actually enable some of these frameworks to run on the HDFS, alongside or in place of MapReduce.”
With the ongoing development of that 0.23 release (now known as Apache Hadoop 2.0) we are beginning to see that process in action. Hadoop 2.0 includes the delivery of the much-anticipated MapReduce 2.0 (also known as YARN, as well as NextGen MapReduce). Whatever you choose to call it, it is a new architecture that splits the JobTracker into its two major functions: resource management and application lifecycle management. The result is that multiple versions of MapReduce can run in the same cluster, and that MapReduce becomes one of several frameworks that can run on the Hadoop Distributed File System.
The first of these is Apache HAMA – the bulk synchronous parallel computing framework for scientific computations, but we will also see other frameworks supported by Hadoop – thanks to Arun C Murthy for pointing to two of them – and fully expect the likes of incremental indexing, ad hoc analytics and graph analysis to be among them.
As we added in Total Data:
“This supports the concept recently raised by Apache Hadoop creator Doug Cutting that what we currently call ‘Hadoop’ could perhaps be thought of as a set of replaceable components in a wider distributed data processing ecosystem… the definition of Hadoop might therefore evolve over time to encompass some of the technologies that could currently be seen as potential alternatives…”
The future of Hadoop is… Hadoop.
June 19th, 2012 — Data management
Platfora’s CEO Ben Werther recently wrote a great post explaining the benefits of Apache Hadoop and its potential to play a major role in a modern-day equivalent of the industrial revolution.
Ben highlights one of the important aspects of our Total Data concept, that generating value from data is about more than just the volume, variety, and velocity of ‘big data’, but also the way in which the user wants to interact with their data.
“What has changed – the heart of the ‘big data’ shift – is only peripherally about the volume of data. Companies are realizing that there is surprising value locked up in their data, but in unanticipated ways that will only emerge down the road.”
He also rightly points out that while Hadoop provides what is fast-becoming the platform of choice for storing all of this data, from an industrial revolution perspective we are still reliant on the equivalent of expert blacksmiths to make sense of all the data.
“Since every company of any scale is going to need to leverage big data, as an industry we either need to train up hundreds of thousands of expert blacksmiths (aka data scientists) or find a way into the industrialized world (aka better tools and technology that dramatically lower the bar to harnessing big data).”
This is a point that Cloudera CEO Mike Olson has been making in recent months. As he stated during his presentation at last month’s OSBC: “we need to see a new class of applications that exploit the benefits and architecture of Hadoop.”
There has been a tremendous amount of effort in the past 12-18 months to integrate Hadoop into the existing data management landscape, via the development of uni- and bi-directional connectors and translators that enable the co-existence of Hadoop with existing relational and non-relational databases and SQL analytics and reporting tools.
This is extremely valuable – especially for enterprises with a heavy investment in SQL tools and skills. As Larry Feinsmith, Managing Director, Office of the CIO, JPMorgan Chase pointed out at last year’s Hadoop World: “it is vitally important that new big data tools integrate with existing products and tools”.
This is why ‘dependency’ (on existing tools/skills) is an integral element of the Total Data concept alongside totality, exploration and frequency.
However, this integration of Hadoop into the established data management market really only gets the industry so far, and in doing-so maintains the SQL-centric view of the world that has dominated for decades.
As Ben suggests, the true start of the ‘industrial revolution’ will begin with the delivery of tools that are specifically designed to take advantage of Hadoop and other technologies and that bring the benefits of big data to the masses.
We are just beginning to see the delivery of these tools and to think beyond the SQL-centric perspective with analytics approaches specifically designed to take advantage of MapReduce and/or the Hadoop Distributed File System. This again though, signals only the end of the beginning of the revolution.
‘Big data’ describes the realization of greater business intelligence by storing, processing and analyzing data that was previously ignored due to the limitations of traditional data management technologies.
The true impact of ‘big data’ will only be realised once people and companies begin to change their behaviour, using this greater business intelligence gained from using tools specifically designed to exploit the benefits and architecture of Hadoop and other emerging data processing technologies, to alter business processes and practices.
April 19th, 2012 — Data management
April 11th, 2012 — Data management
March 8th, 2012 — Data management
Microsoft launches SQL Server 2012. MapR integrates with Informatica. And more.

An occasional series of data-related news, views and links posts on Too Much Information. You can also follow the series @thedataday.
* Microsoft Releases SQL Server 2012 to Help Customers Manage “Any Data, Any Size, Anywhere”
* SQL Server 2012 Released to Manufacturing
* SAS Access to Hadoop Links Leading Analytics, Big Data
* MapR And Informatica Announce Joint Support To Deliver High Performance Big Data Integration And Analysis
* Teradata Expands Integrated Analytics Portfolio
* New Teradata Platform Reshapes Business Intelligence Industry
* Microsoft’s Trinity: A graph database with web-scale potential
* KXEN Announces Availability of InfiniteInsight Version 6, a Predictive Analytics Solution with Unprecedented Agility, Productivity, and Ease of Use
* Software AG Announces its Strategy for the In-memory Management of Big Data
* Attunity and Hortonworks Announce Partnership to Simplify Big Data Integration with Apache Hadoop
* Schooner Information Technology and Ispirer Systems Partner to Deliver SQLWays for SchoonerSQL
* Big Data & Search-Based Applications
* Namenode HA Reaches a Major Milestone
* How Twitter is doing its part to democratize big data
* Dropping Prices Again– EC2, RDS, EMR and ElastiCache
* For 451 Research clients
# SAS outlines Hadoop strategy, previews Hadoop-based in-memory analytics Market Development report
# Pervasive rides the elephant into ‘big data’ predictive analytics Market Development report
# IBM makes desktop discovery and analysis play, shares business analytics priorities Market Development report
# Clustrix launches SDK to tap developer interest in new databases Market Development report
# Continuent and SkySQL team up for clustered MySQL support Analyst note
# MapR gets a boost from Cisco and Informatica Analyst note
And that’s the Data Day, today.
March 8th, 2012 — Data management
We recently speculated that EMC Greenplum’s focus on the integration of its Greenplum HD Hadoop distribution with its Data Computing Appliance (DCA) and Isilon storage technology would mean an increasingly niche role for Greenplum MR- the Hadoop distribution based on MapR’s M5.
Two recent announcements indicate that niche might continue to be a lucrative one for MapR, however. First, Cisco released details of a reference architecture for deploying Greenplum MR on Cisco’s UCS servers. Then Informatica announced a partnership with MapR to jointly support its Data Integration Platform running on MapR’s distribution for Hadoop.
The Informatica relationship also covers bi-directional data integration with Informatica PowerCenter and Informatica PowerExchange, snapshot replication using Informatica FastClone, and data streaming into MapR’s distribution via NFS using Informatica Ultra Messaging. In addition, In addition, the free Informatica HParser Community Edition will be available for download as part of the MapR distribution.
While the partnership with Informatica is a direct one for MapR, the Cisco reference architecture announcement illustrates that the benefit MapR gains from its relationship with EMC Greenplum includes exploiting the company’s leverage with potential partners.

 Subscribe via RSS
Subscribe via RSS